




Introduction
In a recent project I was involved in, I was tasked with handling a data load that was to be performed by external system users. There are several interesting features in APEX and Oracle databases to assist with this type of requirement, such as the UTL_FILE package, the LOAD_DATA API, External tables, etc. Today, I will focus on a straightforward solution: the APEX_DATA_PARSER API.
Presentation of the APEX_DATA_PARSER
This API was introduced in version 19.1 and, in general, it simplifies the importation of files such as XLSX, CSV, JSON, and XML into the database. It also provides tools for data analysis from these files, having an embedded profile.
Data used in the demonstration:
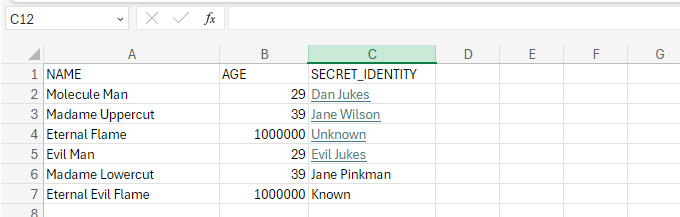
Main utilities
- Function discover: Returns the file profile, detailing its metadata and import/export settings.
select apex_data_parser.discover(
p_content => f.blob_content,
p_file_name=> f.file_name) as profile_json
from files f
where id = :id;
--example of a returned XLSX file:
/*
"file-type":1,
"file-encoding":"AL32UTF8",
"headings-in-first-row":true,
"xslx-worksheet":"sheet1.xml",
"csv-enclosed":"\"",
"force-trim-whitespace":true,
"columns":[
{
"name":"NAME",
"data-type":1,
"data-type-len":100,
"selector":"NAME",
"is-json":false
},
{
"name":"AGE",
"data-type":2,
"selector":"AGE",
"is-json":false
},
{
"name":"SECRET_IDENTITY",
"data-type":1,
"data-type-len":50,
"selector":"SECRET_IDENTITY",
"is-json":false
}
],
"parsed-rows":7
}
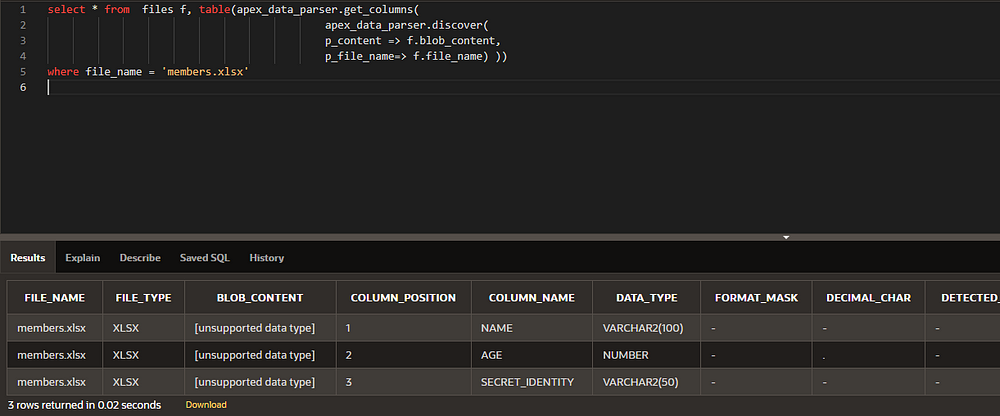
- Functionget_columns: Returns the columns of a profile (previously discussed), very useful for validating if the file meets expectations.
select * from
table(apex_data_parser.get_columns( apex_data_parser.discover(
p_content => :BLOB_CONTENT,
p_file_name=> :FILE_NAME) )
);
FunctionGET_XLSX_WORKSHEETS: Returns the names and sequence of sheets in an XLSX file. Particularly useful when we need to navigate between sheets in an XLSX.

APEX_DATA_PARSER.PARSE
This is the main function of the API, returning a generic table that delivers the data from the file.
Basic example of use:
--Assuming I have a table with stored files:
--There are 300 varchar2 columns
--There are 10 CLOB columns
SELECT line_number, col001, col002, col003, col004, col005, col006, col007, col008
FROM
files f,
TABLE(
APEX_DATA_PARSER.parse(
p_content => f.blob_content,
p_file_name => f.file_name,
p_skip_rows => 1,
p_max_rows => 500 --default is 200
)
)
where f.file_name = :P8_FILE_NAME;
Query using only APEX resources:
Make sure the “file browser” page item is set to “Table” storage type:
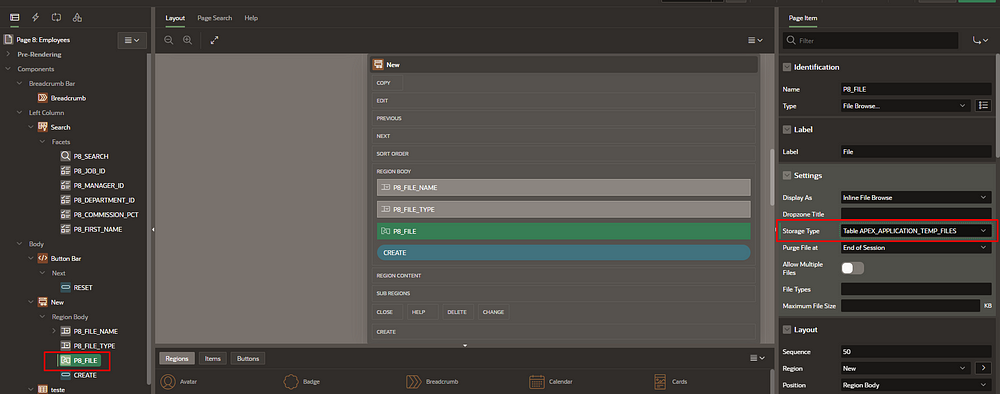
--Query consuming only APEX resources
--Remember that: APEX_APPLICATION_TEMP_FILES is only updated upon submitting the page.
--The file browser item needs to be set with session-state = Per session (persistent)
SELECT line_number, col001, col002, col003, col004, col005, col006, col007, col008
FROM
TABLE(
APEX_DATA_PARSER.parse(
p_content => :PX_FILE, --file browser item, configured to record the file in the APEX_APPLICATION_TEMP_FILES
p_file_name => :PX_FILE_NAME,
p_skip_rows => 1,
p_max_rows => 500 --default is 200
)
);
Practical Example
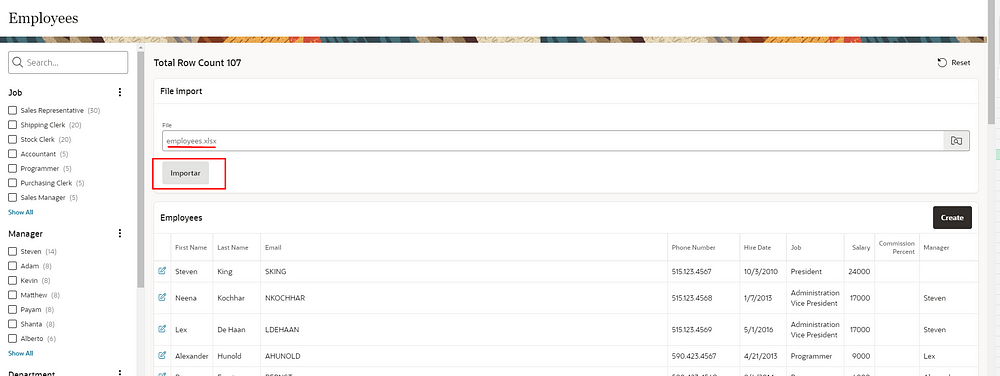
For this demonstration, I created a file import region above an employee report.
When selecting the file and clicking the “Import” button, we will consume employee data from the XLSX file, validating it and adding it to the employee table.
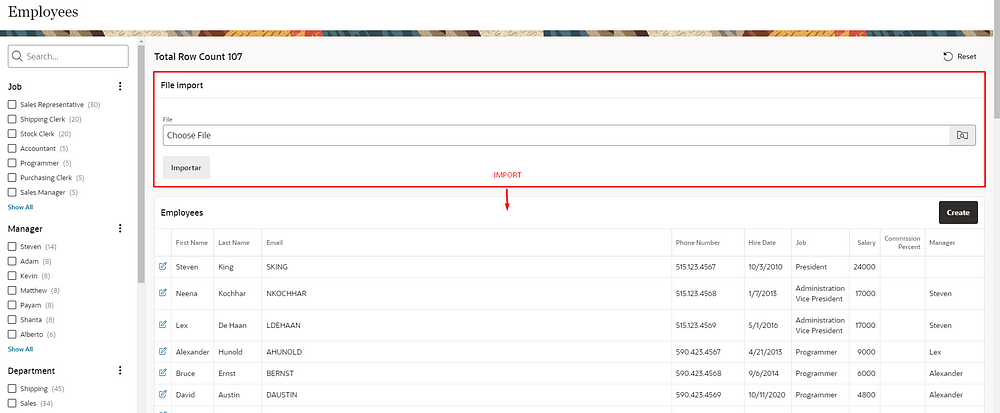
File used:

On the page, under the processes tab, I created a new process under the “processing” group:
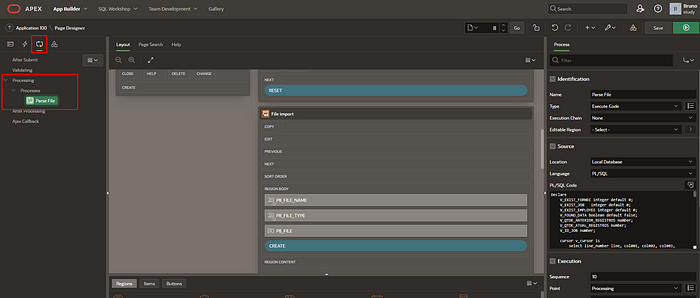
Declare
l_EXIST_EMPLOYEE integer default 0;
l_COUNT_RECORDS_BEFORE number;
l_COUNT_RECORDS_AFTER number;
cursor l_cursor is
select line_number line, col001, col002, col003, col004, col005,
col006, col007, col008, col009, col010, col011, col012, col013, col014, col015, col016
from apex_application_temp_files f,
table( apex_data_parser.parse(
p_content => f.blob_content,
p_add_headers_row => 'Y',
p_max_rows => 500,
p_skip_rows => 0,
p_store_profile_to_collection => 'PROFILE_COLLECTION', -- <OPTIONAL> Creates a collection to store the profile
p_file_name => f.filename ) ) p
where f.name = :PX_FILE;
Begin
/* perform all necessary validations */
--Check how many records are currently in the table to later validate if the inserts were successful
SELECT count(*) INTO l_COUNT_RECORDS_BEFORE FROM OEHR_EMPLOYEES;
for x in l_cursor loop
IF x.line > 1 and x.col001 is not null then --Checks if the file ended or has no data
--Checks if the file contains mandatory information in the expected format
IF X.col001 is null then
RAISE_APPLICATION_ERROR(-20004,'The first name of the employee is null in line '||X.line);
END IF;
--Simple test to check for duplicates
select count(*) into l_EXIST_EMPLOYEE from OEHR_EMPLOYEES
where upper(FIRST_NAME) = upper(X.col001)
and upper(LAST_NAME) = upper(X.col002)
and upper(EMAIL) = upper(X.col003);
--Check if the employee exists in the database
IF l_EXIST_EMPLOYEE > 0 then
raise_application_error(-20003,'The employee '||X.col001||
' with email '|| x.col003 || ' already exists. Line: '||X.line );
END IF;
INSERT INTO OEHR_EMPLOYEES
(
FIRST_NAME,
LAST_NAME,
EMAIL,
HIRE_DATE,
JOB_ID
)
VALUES
(
x.col001,
x.col002,
x.col003,
to_date(x.col004,'DD/MM/YYYY'),
x.col005);
end if;
end loop;
SELECT count(*) INTO l_COUNT_RECORDS_AFTER FROM OEHR_EMPLOYEES;
IF l_COUNT_RECORDS_AFTER = l_COUNT_RECORDS_BEFORE THEN
RAISE_APPLICATION_ERROR(-20006,'Import failed. Please use the standard file model.');
END IF;
End;
In this way, the data load is functioning as expected:

Using the APEX_DATA_PARSER with JSON and XML
JSON
File:
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
"active": true,
"members": [
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": ["Radiation resistance", "Turning tiny", "Radiation blast"]
},
{
"name": "Madame Uppercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown",
"powers": [
"Immortality",
"Heat Immunity",
"Inferno",
"Teleportation",
"Interdimensional travel"
]
}
],
"squadName": "Super Villains squad",
"homeTown": "Metro City",
"formed": 2020,
"secretBase": "Super Villain tower",
"active": true,
"members": [
{
"name": "Evil Man",
"age": 29,
"secretIdentity": "Evil Jukes",
"powers": ["Radiation resistance", "Turning tiny", "Radiation blast"]
},
{
"name": "Madame Lowercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
},
{
"name": "Eternal Evil Flame",
"age": 1000000,
"secretIdentity": "Known",
"powers": [
"Immortality",
"Heat Immunity",
"Inferno",
"Teleportation",
"Interdimensional travel"
]
}
]
}
Parse of the query:
- By default, only the first JSON array is consumed. To consume nested arrays, it's necessary to specify the path:
SELECT line_number, col001, col002, col003, col004, col005, col006, col007, col008
FROM
apex_application_temp_files f,
TABLE(
APEX_DATA_PARSER.parse(
p_content => f.blob_content,
p_file_name => f.filename,
p_row_selector => 'members',
p_add_headers_row => 'N'
)
)
where f.filename = :PX_FILE_NAME

XML
File**:**
<squads>
<squad>
<squadName>Super hero squad</squadName>
<homeTown>Metro City</homeTown>
<formed>2016</formed>
<secretBase>Super tower</secretBase>
<active>true</active>
<member>
<name>Molecule Man</name>
<age>29</age>
<secretIdentity>Dan Jukes</secretIdentity>
<powers>Radiation resistance; Turning tiny; Radiation blast</powers>
</member>
<member>
<name>Madame Uppercut</name>
<age>39</age>
<secretIdentity>Jane Wilson</secretIdentity>
<powers>Million tonne punch; Damage resistance; Superhuman reflexes</powers>
</member>
</squad>
<squad>
<squadName>Super Villains squad</squadName>
<homeTown>Metro City</homeTown>
<formed>2020</formed>
<secretBase>Super Villain tower</secretBase>
<active>true</active>
<member>
<name>Evil Man</name>
<age>29</age>
<secretIdentity>Evil Jukes</secretIdentity>
<powers>Radiation resistance; Turning tiny; Radiation blast</powers>
</member>
<member>
<name>Madame Lowercut</name>
<age>39</age>
<secretIdentity>Jane Wilson</secretIdentity>
<powers>Million tonne punch; Damage resistance; Superhuman reflexes</powers>
</member>
</squad>
</squads>
Parse of the query:
- By default, the first hierarchical structure is consumed. In this case,
<squads>, having 2 rows representing “Super hero squad” and “Super Villains squad” respectively. But since our goal is to bring only the members (tag<member>) we pass the path to this structure:
SELECT line_number, col001, col002, col003, col004, col005, col006, col007, col008
FROM
apex_application_temp_files f,
TABLE(
APEX_DATA_PARSER.parse(
p_content => f.blob_content,
p_file_name => f.filename,
p_row_selector => '/squads/squad/member',
p_add_headers_row => 'N'
)
)
where f.filename = :P8_FILE_NAME
The result will be the same as seen in the JSON parse.
Conclusion
The APEX_DATA_PARSER API, available since version 19.1 of APEX, can greatly assist us in validating and importing data into our database, providing more convenience to the end user. Its powerful tools allow us to:
Navigate between sheets in an XLSX file through the GET_XLSX_WORKSHEETS function
Create a file profile through the DISCOVER function
Return the header value (columns) of the files through the GET_COLUMNS function
Consume the data contained in the file through the PARSE function
It's important to remember that this API has some limitations regarding the maximum amount of data imported, column sizes, and file sizes. Consult the documentation of your version for more details.